

school
27
Jul
2026
07
Aug
2026
Joint ICTP-IAEA Nuclear Energy Management School | (smr 4229)
Physical
Back
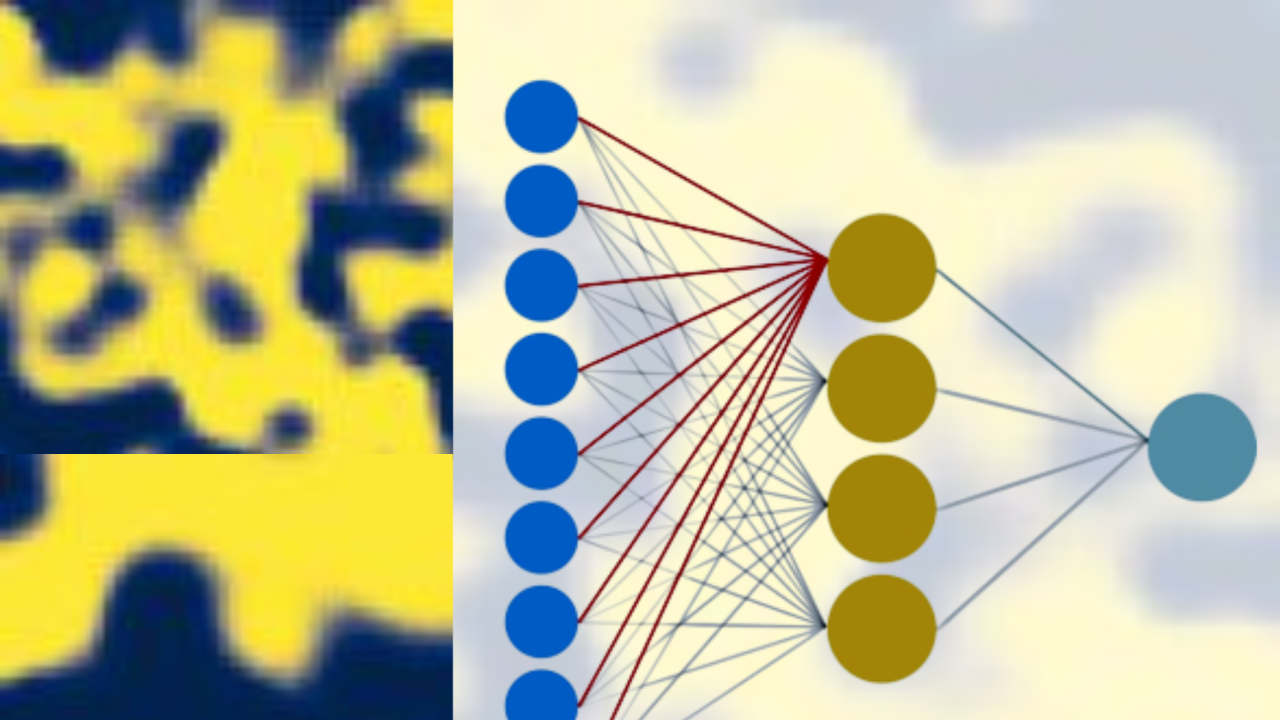
A new paper published in PNAS by Alessandro Ingrosso, a senior postdoctoral fellow in ICTP's Quantitative Life Sciences section, and SISSA researcher Sebastian Goldt, addresses the way in which neural networks learn, i.e. the way in which they build their learning structures, in relation with the input data they are given.
Titled "Data-driven emergence of convolutional structure in neural networks", the paper investigates how neural networks can autonomously discover significant symmetries in their input data, which are crucial in the learning process.
"This was a project that I started during my postdoc at the Center for Theoretical Neuroscience at Columbia University, that had left me with a sort of open question," said Ingrosso. "When I arrived here at ICTP I was looking for methods to solve this open problem. I knew that Goldt could complement my expertise, so, I contacted him and we started working together."
In image recognition problems, the neural networks that are most successful and commonly used are of the so-called convolutional type. These particular kinds of artificial neural networks were originally invented taking inspiration from a biological system, namely the structure of the retina, and the way the visual cortex in the brain responds to images.
The main feature of these networks is that there is a topographical organisation of the cortex response to the external signal. This means that the external world that we see is "divided" in patches that are perceived by localised receptive fields.
"The convolutional structure is usually pre-coded in the network, that is, you have to write it into the network," said Ingrosso. "So our question was: is it possible for the network to learn the convolutional structure directly from input data?"
The reason why convolutional neural networks are so successful in addressing problems of image classification is that they contain in their own structure the property of translation invariance of images. In other words, their performance does not depend on where an element or an object is located within the visual field.
"We first ensured that the network learns autonomously the convolutional structure, that is, that the network develops this internal translational invariant structure - just from the input data," said Ingrosso. "The second thing was to understand, in a very simple network model, why this convolutional structure is influenced only by the properties of the input. What we found is that if the input images have properties similar to those of real-world images, then this results in the emergence of a convolutional structure in the network."
The two researchers developed a simple model of input images that share some basic features with so-called natural images: they are translationally invariant, localised and have rather clear outlines. Using these images as inputs for their neural network resulted in the development of a pattern of localised receptive fields. "We basically analysed, from a theoretical point of view, the dynamics of learning and the resulting network architecture," said Ingrosso. The results could have important impacts on the theory of neural networks and machine learning. "This analysis helped us understand which are the statistical characteristics of the images that determine the development of local receptive fields", added Goldt.
Moreover, these results could be applied to various sensory modalities other than vision, such as sound, analysing the local response to auditory frequencies, or patterns, such as in protein structures.
"This was a really fun project, and we would like to investigate more," said Goldt. "For example, we noticed that networks learn following a sort of hierarchy, starting from the simplest statistics of the inputs and proceeding later with more complicated ones. And we would like to understand how this happens."
--Marina Menga